What is CloneSPEECH?
CloneSPEECH converts text into realistic speech using a reference voice you provide. A "reference voice" is the voice style you want generated — it can be a recording you upload, one you record on-the-fly, or a reference voice you’ve already saved in your account.
How it works — step by step
-
1
Provide a reference voice
CloneSPEECH needs a reference voice — the voice in which you want the script generated. You have three options:
- Record on the go: Use the "Start Recording" button to capture a short sample directly from your browser.
- Upload an audio file: Upload a clean audio file (MP3/WAV). Make sure the sample has minimal background noise and clear speech for best results.
- Use an existing reference voice: Select a reference voice you already generated or saved in your VoiceAI library.
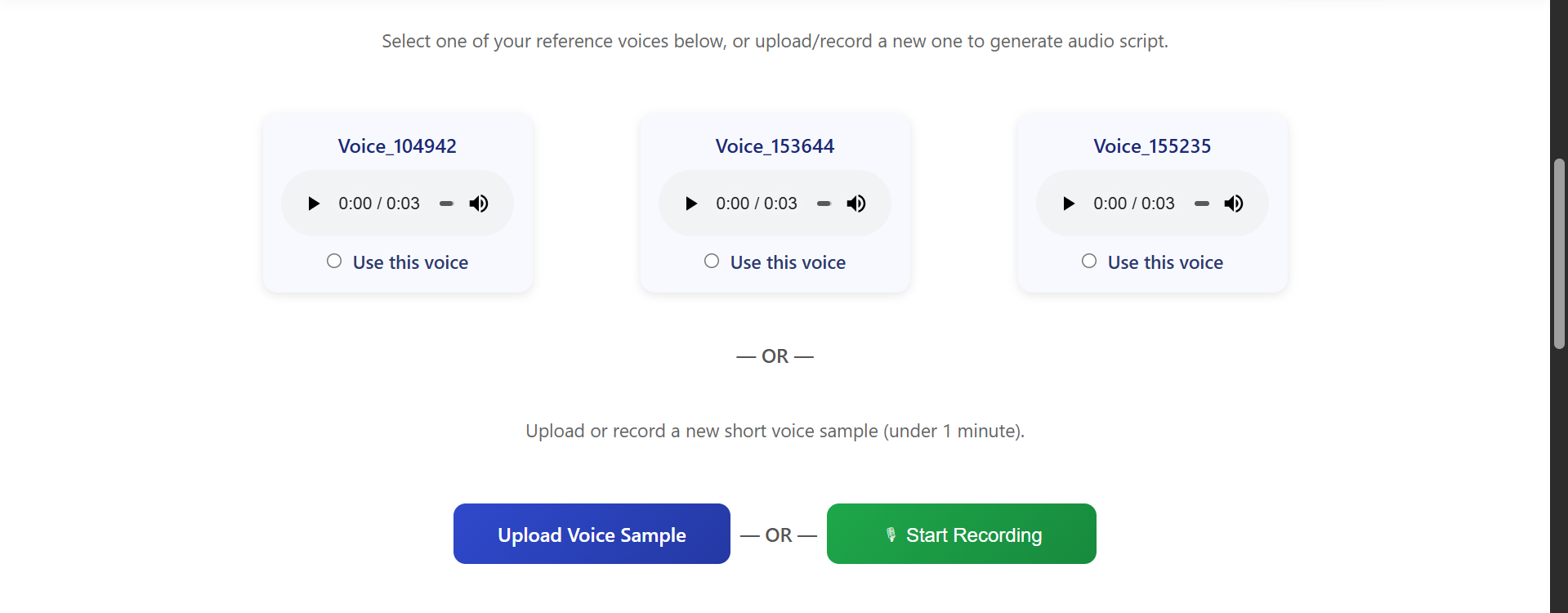
Screenshot: Upload, Record, or choose an existing reference voice from the home page.
Tip: Record in a quiet room and use a decent microphone. Short samples (10–60s) work well.
-
2
Prepare your script (text)
You can either type or paste your script into the text box (max 2000 characters) or upload a file. Supported formats: .txt, .docx, .pdf.
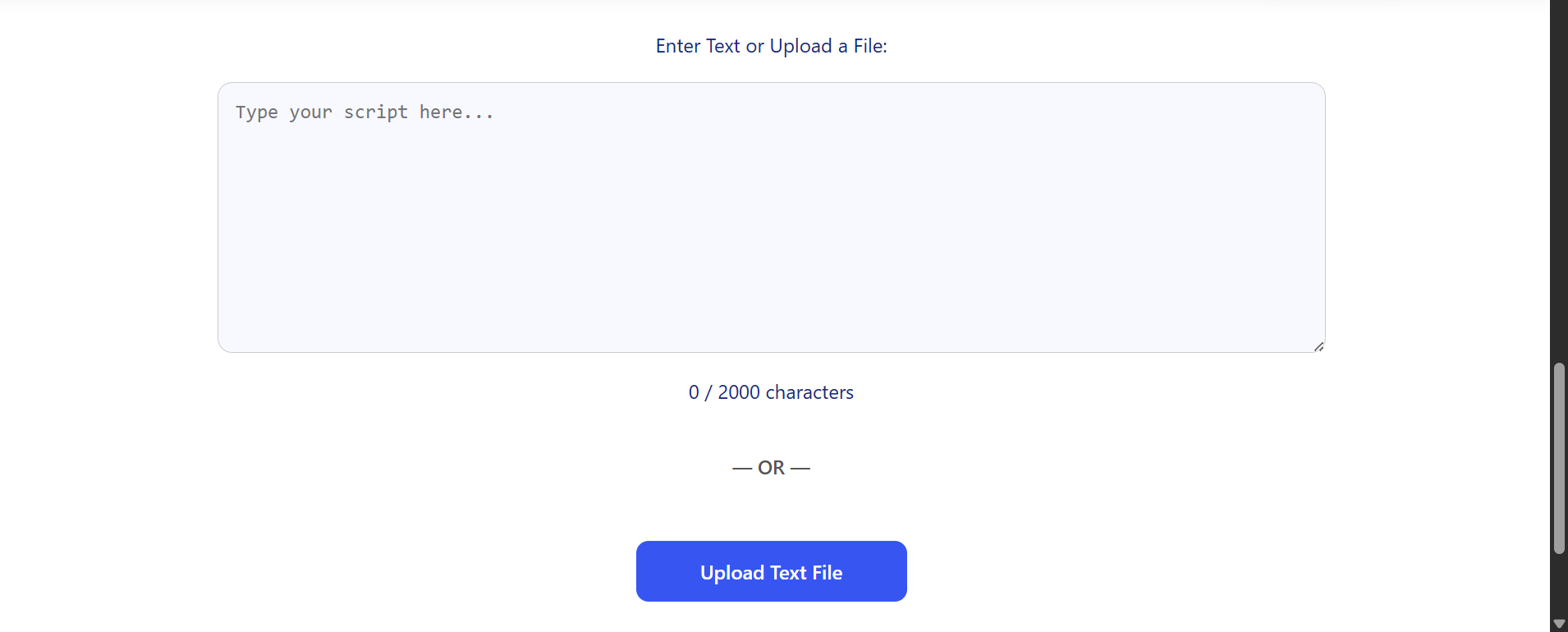
Screenshot: Text area and file upload controls on the generate section.
Note: 2000 characters is roughly 300–350 words — for longer scripts, split them into multiple generations.
-
3
Generate speech
Once you have a reference voice selected (or recorded) and your script ready, click the "Generate Speech" button. CloneSPEECH will analyze the reference voice and produce an audio file of your text in that voice.
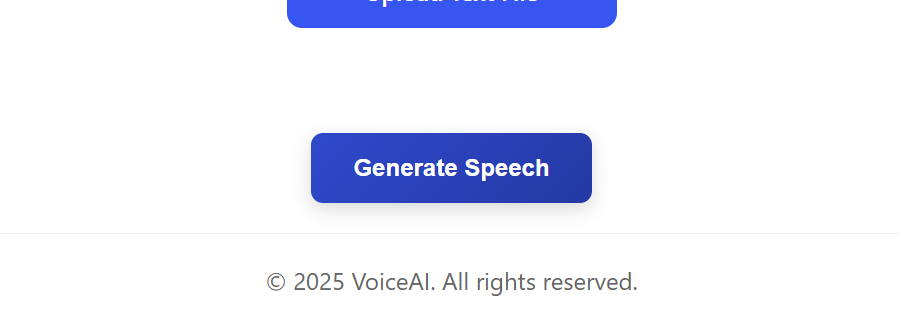
Screenshot: Click Generate and wait for the preview to appear.
A loader overlay will appear while generation runs — this may take a few seconds depending on script length.
-
4
Preview, download & manage
After the generation completes you can:
- Preview the generated audio in the web player.
- Download the file (MP3) to use in your projects.
- Save the generated file to your scripts library for future reuse.
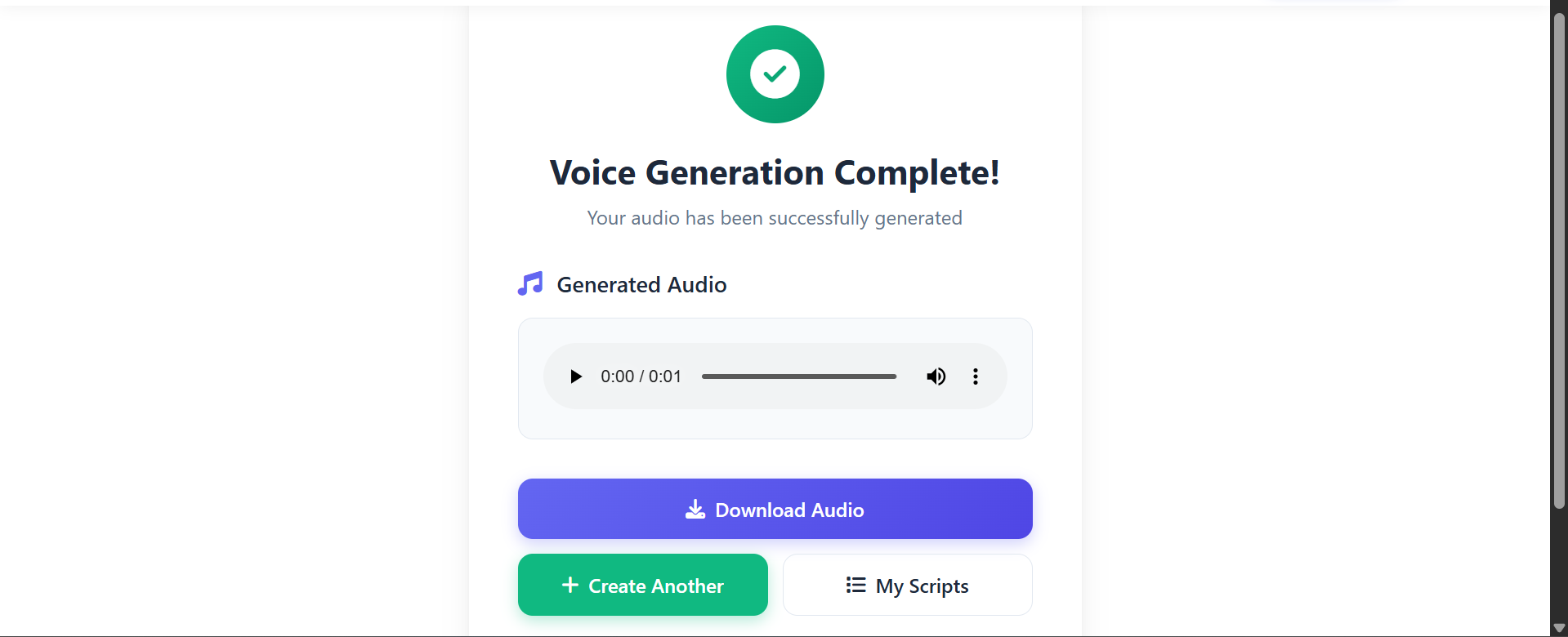
Screenshot: Preview controls and download/save actions.
Best practices for best results
- Clear recording: Reference voice should be clean, recorded in a quiet environment without background noise.
- Single speaker: Use a single speaker sample for more consistent results.
- Avoid music/sfx: Do not include music or heavy sound effects in the reference voice sample.
- Short samples ok: 10–60 seconds is sufficient for many voices — longer samples can improve nuance.
Watch a quick tutorial
Play the 1–2 minute video below to see these steps in action.